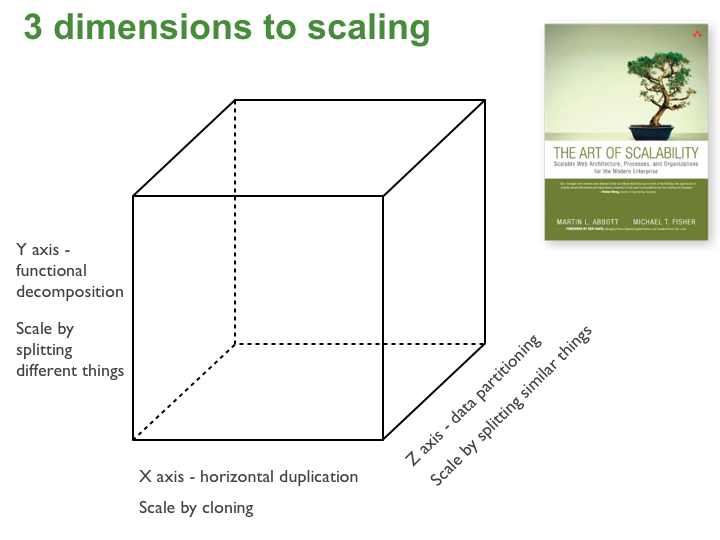
Scale cube
หลังจากไม่ได้เขียน Blog ไปนานเพราะขี้เกียจกับอยากนอนอืดเสาร์อาทิตย์ พอมาถึงจุดที่เละเทะเกินเยียวยาเลยต้องหาอะไรทำแล้วไม่งั้นจะกู่ไม่กลับ เลยคิดว่ากลับมาเขียน Blog ดีกว่า เพราะยิ่งเขียนยิ่งต้องหาอะไรมาเขียนต่ออีกเรื่อยๆ จะได้อ่านหนังสือ ประจวบเหมาะกับบริษัทอยากจะโล๊ะ Project เก่าแล้วทำเป็น Micro service ซึ่งตอนนี้เราก็ยังไม่รู้ว่าควรจะทำดีไหม แต่เห็นแล้วมันน่าจับแยกมากเพราะมันเริ่ม complex มาก บ่นมากแล้วมาพูดถึงเนื้อหาตอนนี้กันดีกว่า วันนี้จะมีพูดเรื่อง Scale cube กันดีกว่า
scale cube ก็คือรูปที่เห็นด้านบนนั่นแหละครับ รูปนี้มาจากหนังสือ The Art of Scalability ซึ่งในรูปคือวิธีในการ scale ตัว Application ไปในทิศทางใด โดยเขาแบ่งออกเป็น 3 (ก็มันเป็นลูกบาศก์มันก็ต้อง 3 แกนอยู่ละ) ทิศทางคือ คือ x, y, z (Dragon Cannon)
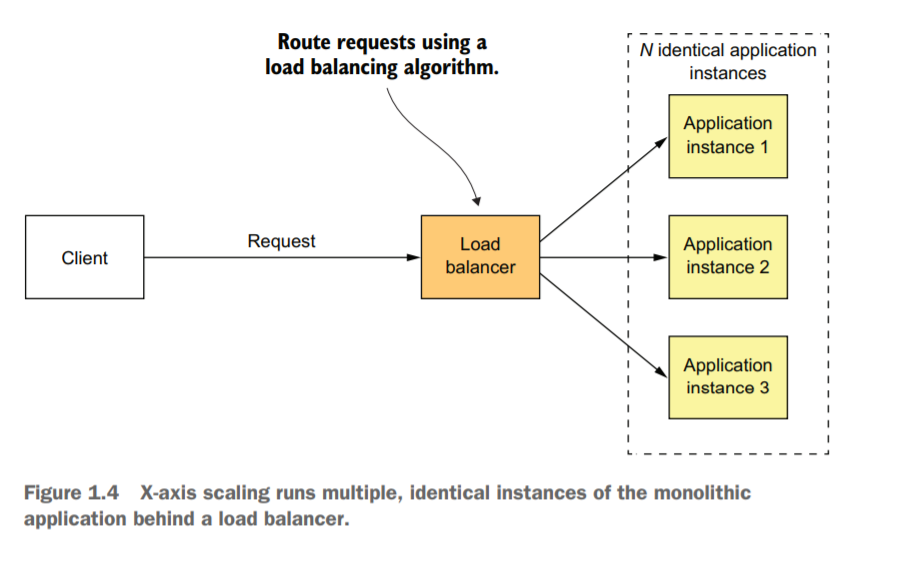
แกน X
Scale โดยการ Duplicate ตัว Application แล้วให้ตัว Load balance กระจายงานเข้าไปให้แต่ละ Node
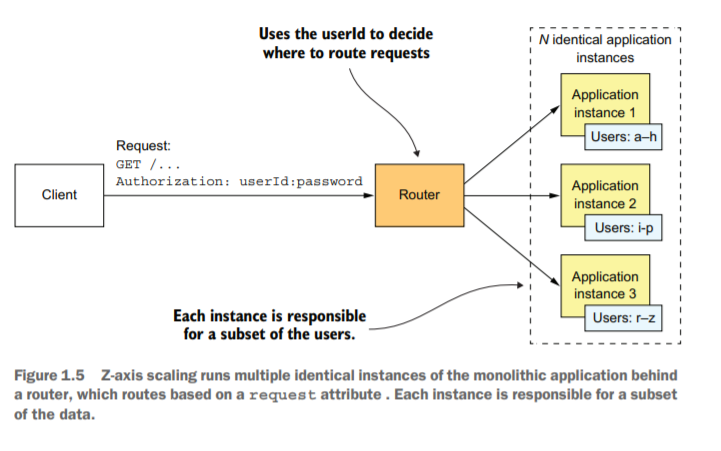
แกน Z
Scale โดยการ Duplicate ตัว Application เหมือนกับแกน X แต่ก่อนจะกระจายงานจะมีตัวตัดสินใจโดยตัดสินใจโดยใช้เงื่อนไขเกี่ยวกับ Data เช่น แบ่งตาม user ที่ส่ง Request เข้ามา เช่น a - h เข้าเครื่องที่ 1 ดังภาพตามหนังสือ ซึ่งแกน X กับ แกน Z ต่างกันคือ แกน Z สนใจเงื่อนไขเกี่ยวกับ Data เป็นเงื่อนไขในการกระจายงาน ต่างจากแกน X จะ กระจายตามแบบเท่าเทียม หรือ เช็คว่าตัวไหนมีชีวิตอยู่บ้าง
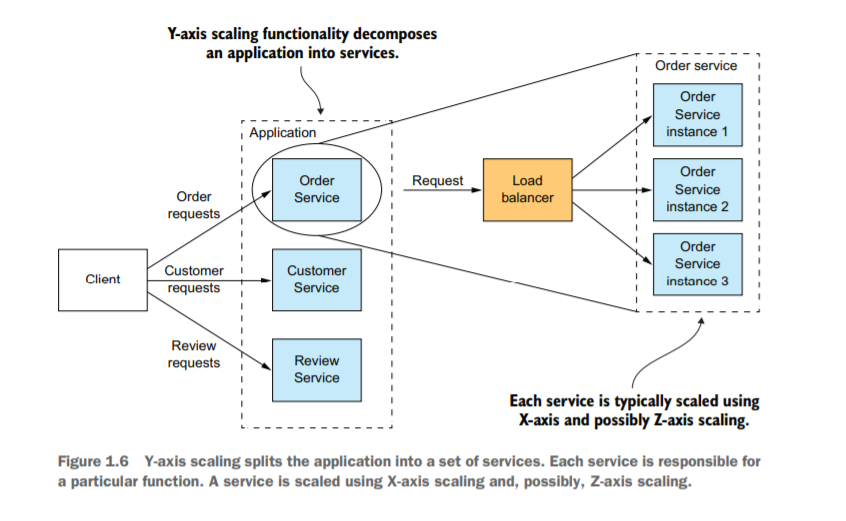
แกน Y
Scale โดยการแตก Application ของเราให้เป็นส่วนย่อยๆ โดยอาจจะแบ่ง Application เป็นหลายๆ Application ความรับผิดชอบ ดูได้จากภาพตัวอย่าง ที่ทำการแยก Application จากเดิมภาพที่ แกน X , แกน Z จะเป็น Application ใหญ่ๆ Application เดียว แต่อันนี้เราจะแยก Application ของเราเป็น Application ย่อยๆ 3 Service ดังภาพ คือ Order service, Customer service, Review service
ฉันยังคงสงสัย (รู้สึกอยู่ไม่หาย ก็คิดว่าเธอคงรักกัน)
จากการอ่านและคิดตามก็เห็นภาพตามคร่าวๆว่าการ scale แต่ละแกนมัน scale ยังไง ในตอนที่ทำงานวิธี scale ที่ง่ายที่สุดคือแกน X ครับ คือแค่ clone เครื่อง วางหลัง load balance ก็ใช้งานได้เลย ในส่วนของแกน Z นั้นแทบจะเหมือนแกน X เลย แต่ต่างกันตรงที่มีตั้งเงื่อนไขว่าจะ routing request ตามอะไร ซึ่ง อันนี้ผมยังไม่เคยได้ทำในงานจริงที่เคยลอง เพราะต้องมาเขียนตัวจัดการ Route ของ data ซึ่งเพิ่มงาน ส่วนแกนสุดท้ายคือแกน Y อันนี้คือแบบใหม่ที่เคยได้ยินเลยคือการแยก Application ออกเป็น Application ย่อยๆไปเลยซึ่งมันคือการจะทำ Microservice เนี่ยแหละ
ซึ่งเมื่ออ่านแล้วเราก็เข้าใจว่าการ scale เนี่ยมันไม่ต้องทำไปในทางใดทางหนึ่ง เราสามารถทำผสมกันได้ในทุกแกนเลยทำให้เขายกตัวอย่างเป็น cube เพราะเวลาเราบอกพิกัดใน cube นั้นเราต้องบอกพิกัด 3 แกน เช่นกัน application ของเราก็สามารถ scale ได้หลายทางเช่น แบ่งเป็น 3 service คือ scale ไปในแกน Y แล้ว service ที่ 1 Duplicate เป็น 3 ตัว แบบเท่ากันโดยไม่สนใจ data อันนี้คือ scale ไปในแกน X ส่วน service ที่ 2 scale เป็น 3 เครื่อง แล้ว routing ด้วย id ของข้อมูลโดยใช้การ mod ด้วย 3
"สิ่งที่ผมเขียนขึ้นเป็นเพียงความรู้และความเข้าใจของบุคคลเพียงบุคคลเดียว ดังนั้นอย่าเพิ่งเชื่อในสิ่งที่ผมเขียนและอธิบาย ลองทำความเข้าใจว่ามันเป็นจริงอย่างนั้นไหมและลองหาแหล่งอ้างอิงอื่นๆว่าเขามีแนวคิดอย่างไร เรื่องการ Design และวิธีการใช้งานไม่มีถูกไม่มีผิดมีแต่เหมาะสมกับงานนั้นไหม"
ref :
https://microservices.io/articles/scalecube.html
https://manning-content.s3.amazonaws.com/download/2/031dbdc-2223-4304-bad9-bb2a83d88899/sample_ch01_Richardson_Microservices-Patterns_October10.pdf