Concurrency Part 3 : ปัญหา Phantom และ อธิบายเกี่ยวกับ Isolation level เพิ่มเติม

ผมเขียนเกี่ยวกับ Concurrency ไว้หลายตอน คุณสามารถกด Link ด้านล่างเพื่ออ่านที่เกี่ยวกับ Concurrency ตอนต่างๆได้เลย
- Concurrency Part 1 - ปัญหาพื้นฐานเมื่อใช้งาน Database พร้อมกัน
- Concurrency Part 2 - Transaction , ACID และ Isolation level ของ Relational Database
- Concurrency Part 3 - ปัญหา Phantom และ อธิบายเกี่ยวกับ Isolation level เพิ่มเติม
ตอนที่แล้วเราได้เรียนรู้ Isolation level ทั้ง 4 ระดับแล้วก็มีติดกันเรื่องปัญหา Phantom ว่าคืออะไร ตอนนี้เราจะมาอธิบายว่าปัญหา Phantom คืออะไร แล้วก็อธิบายว่าทำไม Isolation level นี้ถึงแก้ปัญหาแต่ละปัญหาได้ เพราะตอนที่แล้วไม่ได้อธิบาย
Phantom
ในตอนก่อนเวลาเราพูดถึงปัญหาเราจะมองว่าปัญหาเกิดขึ้นกับ field บน Row ที่มีอยู่ในระบบ และเรามักจะสนใจที่ Row ที่เราสนใจ จนเรามองข้ามปัญหานึงไปนั่นก็คือปัญหา Phantom นั้นเอง ลองนึกภาพตามที่เรา Query ข้อมูลหลายๆ Row ว่าง่ายคือ WHERE เป็น Range นั่นเอง คราวนี้มีการสั่ง Insert ข้อมูลเข้าไปในระบบ อะไรจะเกิดขึ้นเพราะ Row ที่ Insert เข้าไปเป็น Row ใหม่ ไม่เคยมีอยู่จริง คราวนี้ก็เกิดปัญหาสิ
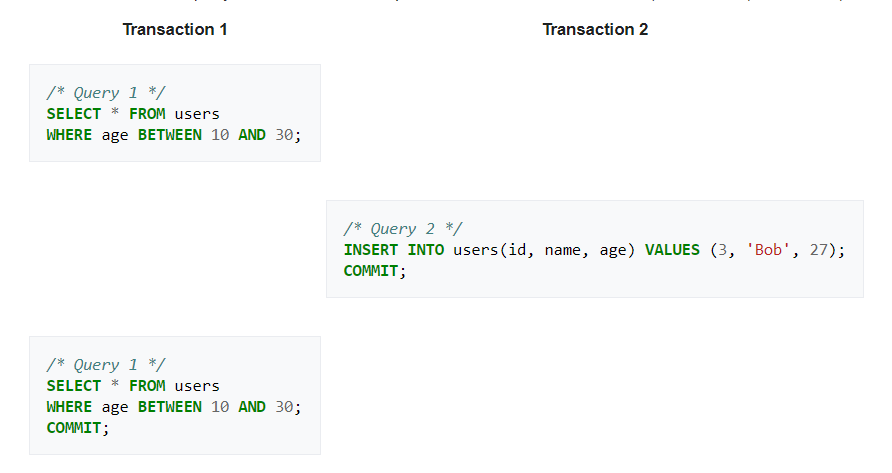
รอบนี้ขี้เกียจทำรูปละเหนื่อยเกินเลยขอใช้รูปจาก Wikipedia แทน ซึ่งถ้าเราอยากจะการันตีไม่ให้เกิดปัญหานี้เราแค่กำหนด Isolation level เป็นระดับ Serializable ซะก็จะสามารถแก้ปัญหานี้ได้
แล้วใช้ Isolation level อะไรดีล่ะ
ถ้าอยาก Play safe สุดก็ตั้งระดับเป็น Serializable หมดเลยก็จบเลยสิ ซึ่งจริงๆมันก็เป็นคำตอบที่ถูกครับ แต่โดยภาพรวมระบบอาจทำงานช้าลงเพราะการทำ Serializable มันต้องทำงานเสมือนว่า Transaction ที่เข้ามาต้องเสมือนว่าทำงานต่อกัน ที่ใช้คำว่าเสมือนเพราะเขาสนที่ผลลัพธ์ว่าผลลัพธ์หลังจากการทำงานแล้วผลลัพธ์เหมือนกันไหม แต่โดยการเช็คนั้นก็วิธีการเช็คที่กินเวลาอยู่ ดังนั้นหากการเลือกใช้ระดับ Isolation level ให้เหมาะกับงานน่าจะตอบโจทย์กว่า
Read Uncommited
เฮ้ยงานไหนมันจะใช้ Read Uncommited วะ อ่านข้อมูลที่ยังไม่ Commit ซึ่งสำหรับงานที่ทำมันหายากมาก แต่เคยที่เจอคืองาน Gen Ref คือมันมีคน Design วิธี Gen ref หลายๆ Ref โดยใช้ตารางเดียวกัน คือถ้ามันมี Ref เดียวตารางเดียวมันจะง่ายมากโดยการใช้ Auto increment ในการบอกว่ามันคือ Ref เท่าไหร่ แต่คราวนี้พอใช้ตารางเดียวกันมันใช้ Auto increment ไม่ได้ คราวนี้ก็ต้องมาใช้การนับว่า Ref ที่ต้องการมันมีไปกี่อันแล้วนั่นเอง
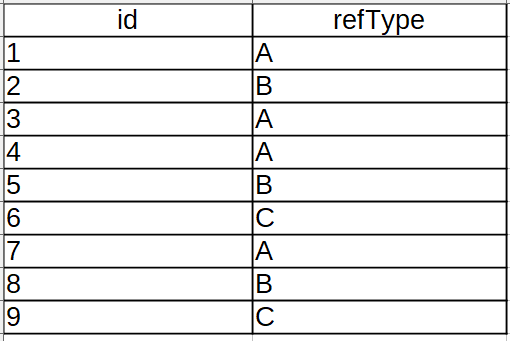
อันนี้ตัวอย่างตารางมีข้อมูลประมาณนี้ อ่านถึงตรงนี้เหมือนไม่มีปัญหาอะไรใช่ไหมครับ คราวนี้ลองนึกภาพตามว่ามี Request รัวๆเข้ามาแล้วต้องใช้ table นี้ในการ gen ref สภาพจะเป็นประมาณนี้
step การทำงานก็จะประมาณว่า
1 | INSERT INTO tab_gen_ref (refType) VALUES ('A') |
เมื่อ insert เสร็จเราจะได้ auto increment นั้นมา จากนั้นเราจะ Count จำนวนตัวเลข ref ที่เราต้องการจากใช้คำสั่ง
1 | -- x คือ id auto increment ที่เรา insert ลงไปเมื่อกี้ |
ซึ่งถ้าจำลองการทำงานมันจะได้ดังภาพด้านล่าง
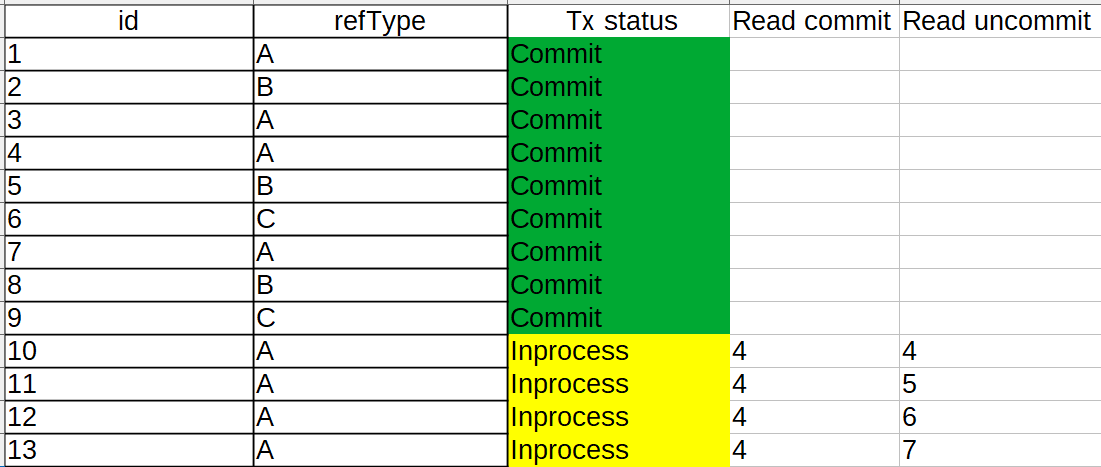
ซึ่งเราจะเห็นว่าถ้าเราใช้ Isolation level ระดับ Read commited จะเกิดปัญหาเพราะเขาไม่อ่านข้อมูลที่ยังไม่ commit จำนวนที่ count ได้มันเลยไม่ได้อย่างที่ต้องการ แต่ถ้าเราใช้ Read Uncommited จะสามารถอ่านข้อมูลที่ไม่ commit ได้ทำให้ผลลัพธ์ได้อย่างที่เราต้องการ
Read Commited
มาถึง Read commited อันนี้เป็นระดับที่ใช้บ่อยระดับ สำหรับระดับนี้ตอนที่ผมทำงานก็จะเป็นงานประมาณว่า อ่านไปใช้อย่างเดียวไม่ได้มีผลกับการเอาไปทำอย่างอื่น เช่น ดึงเอาไปออกฟอร์มบางอย่าง โดยฟอร์มนั้นอ้างอิงตามเวลานั้น ไม่ได้สนใจว่าหลังจากดึงข้อมูลจะเปลี่ยนหรือไม่ประมาณนั้น
Repeatable reads
สำหรับระดับนี้เป็นระดับที่ผมใช้บ่อยสุดเพราะต้องการป้องกันปัญหา Lost update เลยมาใช้ระดับนี้ เพราะงานที่ผมทำส่วนใหญ่จะเป็นการทำการ Update ข้อมูล ดังนั้นเวลา select ข้อมูล row นึงขึ้นมาเพื่อทำการ update อาจมีอีกคนพยายามดึงข้อมูลไป Update หรือกำลังอยู่ในการ Update เนื่องจากไม่อยากให้อยู่ในสถานการณ์แบบนั้นผมเลยเลือกใช้ Isolation level นี้
Serializable
ส่วนอันนี้ผมไม่เคยมีโอกาสได้ใช้งานจริงๆเลยเพราะยังไม่ค่อยเจองานไหนใช้ Isolation ระดับนี้เพราะมันเข้มสุด แต่จริงๆก็มีงานที่เคยคิดว่าอาจจะต้องใช้แน่ๆคือออก Report แบบที่ต้องการความแน่นอนมากๆ ประมาณว่าเชื่อข้อมูลตอน Report นั้นออกมา (Transaction commit แล้ว) พูดตรงนี้อาจจะงงนิดหน่อยเรามาอธิบายด้วยรูปภาพ
ถ้าเทียบกันจะประมาณว่าถ้าใช้ Repeatable reads นั้นเราจะเชื่อข้อมูลตอนที่ดึงครั้งแรกเท่านั้นเพราะถ้ามีการ insert ข้อมูลเข้าไปก็จะไม่มีอะไรเกิดขึ้น (ระดับนี้ไม่กัน Phantom) แล้วการทำงานก็จบลง
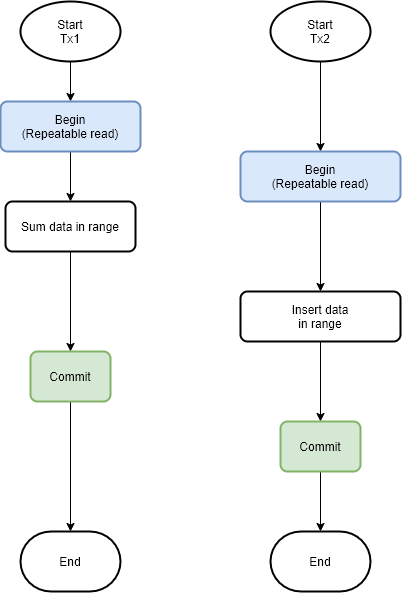
ถ้าโจทย์ของการออก Report นี้คือจะเชื่อ Report ตอนออกเสร็จ ระดับ Repeatable read จะไม่ตอบโจทย์เพราะตอน Commit นั้นมีการ insert ข้อมูลไปก่อน แต่ถ้าอยากจะเป็นตามโจทย์ก็ต้องใช้ Serializable เพราะระดับนี้จะการันตีไม่เกิด Phantom ดังภาพ ซึ่งจะเกิดได้สองกรณีแล้วแต่การ Implement ของ DBMS
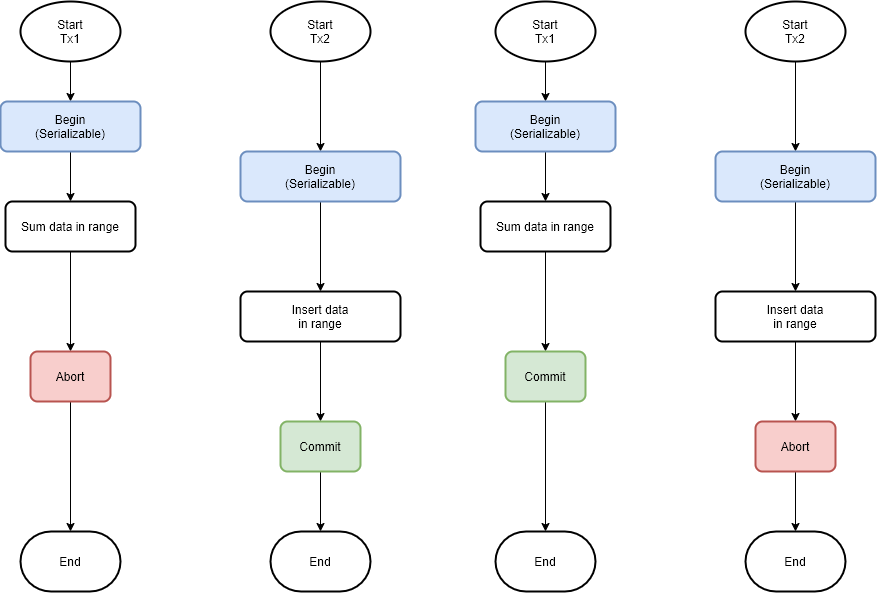
หมดละเรื่องนี้
สำหรับเรื่องเกี่ยวกับ Concurrent นั้นผมคงจะหมดเรื่องที่เล่าให้ฟังละ และด้วยเนื้อหาทั้ง 3 ตอนก็น่าจะพอช่วยให้โปรแกรมเมอร์น้องใหม่หลายๆคนที่หลงเข้ามาอ่านพอจะเห็นภาพว่ามันมีปัญหา Concurrent อะไรเกิดขึ้นบ้างแล้วถ้าสมมุติใช้ RDBMS แล้วล่ะจะใช้ Isolation level อะไรในการแก้ปัญหา ในส่วนของตอนถัดไปนั้นผมอาจจะมาเขียนเกี่ยวกับเรื่องการทำ Transaction ระหว่าง Application หรือ ทำ Transaction ระหว่าง Microservice
Reference
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-95-51.pdf
https://en.wikipedia.org/wiki/Isolation_(database_systems)
เพลงประกอบการเขียน Blog
เพลงนี้เป็นเพลงใหม่ของวง Meltmallow แต่น่าเสียดายที่วงจะปิดตัวลงในสิ้นปีนี้ ผมชอบวงนี้มากเลยนะเพราะเขาทำเพลงได้ดีทุกเพลงเลย โดยเพลงนีชื่อ My moon ซึ่งเนื้อเพลงมีความหมายดีมาก ดนตรีเศร้าๆ ฟังแล้วนึกถึงใครสักคนที่มีความหมายกับเรา