Concurrency Part 4 - ทดสอบการใช้ Isolation Level เพื่อแก้ปัญหา Lost update

ผมเขียนเกี่ยวกับ Concurrency ไว้หลายตอน คุณสามารถกด Link ด้านล่างเพื่ออ่านที่เกี่ยวกับ Concurrency ตอนต่างๆได้เลย
- Concurrency Part 1 - ปัญหาพื้นฐานเมื่อใช้งาน Database พร้อมกัน
- Concurrency Part 2 - Transaction , ACID และ Isolation level ของ Relational Database
- Concurrency Part 3 - ปัญหา Phantom และ อธิบายเกี่ยวกับ Isolation level เพิ่มเติม
ตอนที่แล้วผมเขียนถึงปัญหา Phantom และสรุปว่าปัญหาไหนควรใช้ Isolation level อะไร ซึ่งจริงๆมันก็น่าจะจบเกี่ยวกับเรื่อง Isolation level แล้วแหละ แต่เมื่อไม่กี่เดือนที่ผ่านมาผมดันนึกสนุกว่าแต่ละ DBMS แต่ละเจ้าเช่น MariaDB, SQLServer, Postgres เนี่ยเขาจะทำให้ Isolation level ได้ตามที่เราคิดรึเปล่า ซึ่งจากการทดลองก็ทำให้ผมเหวอไปนิดนึง ก็เลยมาลองทำการทดลองพิสูจน์เรื่อง Isolation แบบจริงจังดู ซึ่งผมคิดว่ามันอาจมีประโยชน์กับคนอื่นด้วยก็เลยมาเขียนลง Blog เลยดีกว่า
ผมยึด Isolation level ตามมาตรฐาน SQL92 ซึ่งคือมาตรฐานกลางที่ออกมาเพื่อให้ DBMS เจ้าต่างๆเนี่ยทำตาม เวลาคุยกันจะได้ยึดหลักว่าฉันทำตาม Standard version SQL92 นะ ซึ่งแปลว่า DBMS ของฉันทำแบบนั้นแบบนี้ได้ ซึ่งผมมองว่ามันเป็นเรื่องที่ดีมากเลย เพราะถ้าต่างคนต่างมีมาตรฐานนะ คนใช้งานคงปวดหัวในเปรียบเทียบ DBMS แต่ละเจ้า อีกทั้งศัพท์ของแต่ละเจ้าอาจไม่เหมือนกันอีก ลองนึกถึงระบบสีสมัยก่อนมี RGB สิครับ การจะบอกสีกันนี่จะบอกกันลำบากน่าดู
ส่วนปัญหาต่างๆสามารถไปอ่านได้ในตอนเก่าๆหรืออยากอ่านแบบจริงจังสามารถอ่านได้ที่ paper : https://www.cs.umb.edu/~poneil/iso.pdf นี้นะครับ
การทดลอง
สถานการณ์ที่จะทำการทดลอง
ในการทดลองนั้นเราจะจำลองสถานการณ์ Lost update เป็นสองสถานการณ์หลักๆดังภาพ
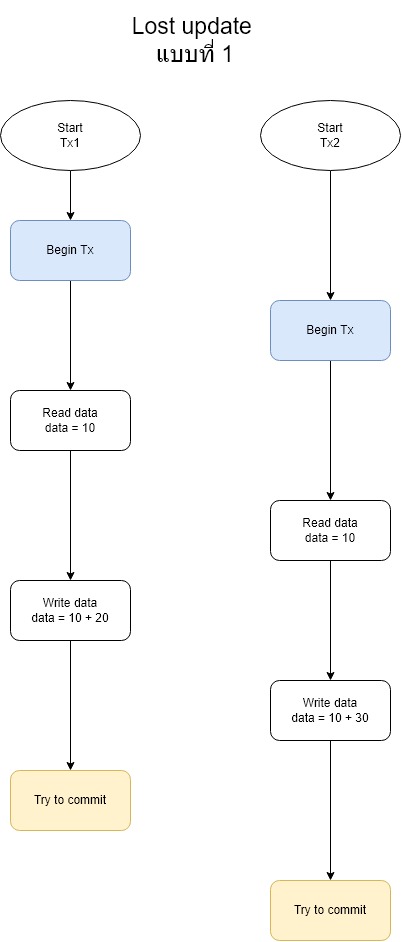
กรณีนี้คือให้ Tx1 ทำการเริ่มก่อนและทำการอ่านข้อมูลก่อนและทำการพยายาม Commit ก่อน
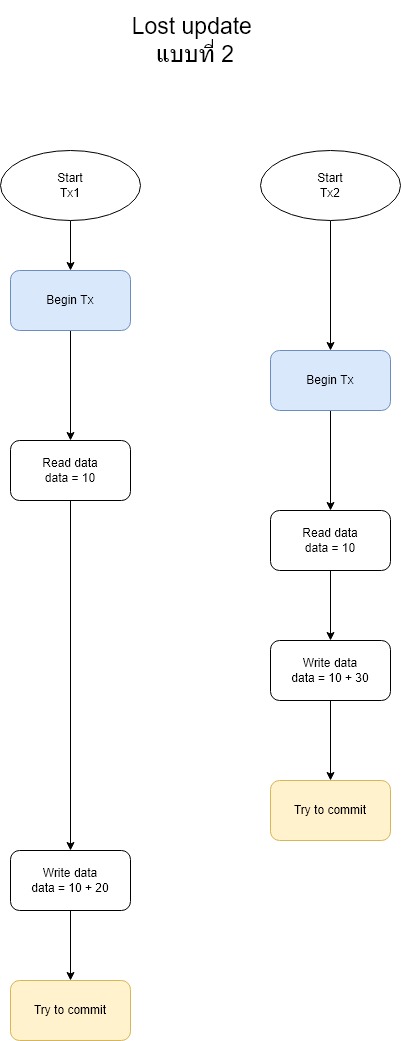
กรณีนี้คือให้ Tx1 เริ่มก่อนอ่านข้อมูลก่อน แต่จะให้ Tx2 ทำการพยายาม commit ก่อน
โดยทั้ง 2 กรณีนั้นจะเกิดปัญหา Lost update แน่นอน เพราะทั้ง 2 Transaction ต่างอ่านค่า data ที่มีค่าเป็น 10 มา แล้วนำไปบวกกับค่าของตัวเอง แล้วทำการ update ซึ่งแน่นอนว่าค่าไม่ถูกต้องแน่นอน และอีกเหตุผลที่ทำ 2 กรณีนั้นก็เพื่อตรวจสอบด้วยว่าถ้ากรณีแตกต่างกันระดับ Isolation จะสามารถแก้ปัญหาได้ทั้ง 2 กรณีหรือไม่ ซึ่งจริงๆแล้วกรณีอาจมีมากกว่านี้อีก
ในการทดลองเราจะให้ 2 Transaction ที่ทำงานนั้นมี Isolation level ต่างกันด้วย ซึ่งเราจะทดลองทุก Isolation level มาเจอกันเลย คือตั้งแต่ READ UNCOMMITED เจอ READ UNCOMMITED ไปจนถึง SERIALIZABLE เจอ SERIALIZABLE รวมแล้วเป็นไปได้ทั้งหมด 16 รูปแบบ
DBMS ที่จะทำการทดลอง
ผมจะทำการทดลองบน DBMS เจ้าดังๆ และสามารถ Run บน Docker ได้ ซึ่งนั่นก็คือ
- MySQL version : 8.0.28
- MariaDB version : 10.7
- SQL Server version : 2019
- Postgres version : 13
- DB2 version : 11.5.7.0
ทดลองบน Spring jpa
เนื่องจากผมเป็นถนัดการเขียน Java และใช้ Framework Spring ดังนั้นถึงทำการทดลองโดยใช้ Spring boot jpa โดยจะใช้การเขียน Code จำลองให้เกิดเหตุการณ์แบบนั้น โดยสร้าง thread ขึ้นมา 2 thread ขึ้นมาพร้อมกัน แต่ละฝ่าย Start transaction ที่ Isolation level ตามที่ได้อธิบายในสถานการณ์ที่จะทดลอง จากนั้นเก็บผลลัพธ์ว่าจะเกิดอะไรขึ้น โดย Source code ทั้งหมดจะอยู่ที่ https://github.com/surapong-taotiamton/test-tx ท่านที่อ่านสามารถไปเช็คได้ว่าผมเขียนถูกไหม หรือทดลองซ้ำดูว่ามันได้ผลลัพธ์เหมือนกันไหม ซึ่งถ้ามีตรงไหนผิดพลาดสามารถแจ้งผมได้เลยครับว่าผิดตรงไหน เดี๋ยวผมจะรีบแก้ให้ถูกต้อง และแก้ไขข้อมูลให้ถูกต้องจะได้ไม่เกิดความเข้าใจผิด
ผลการทดลอง
MySQL version : 8.0.28
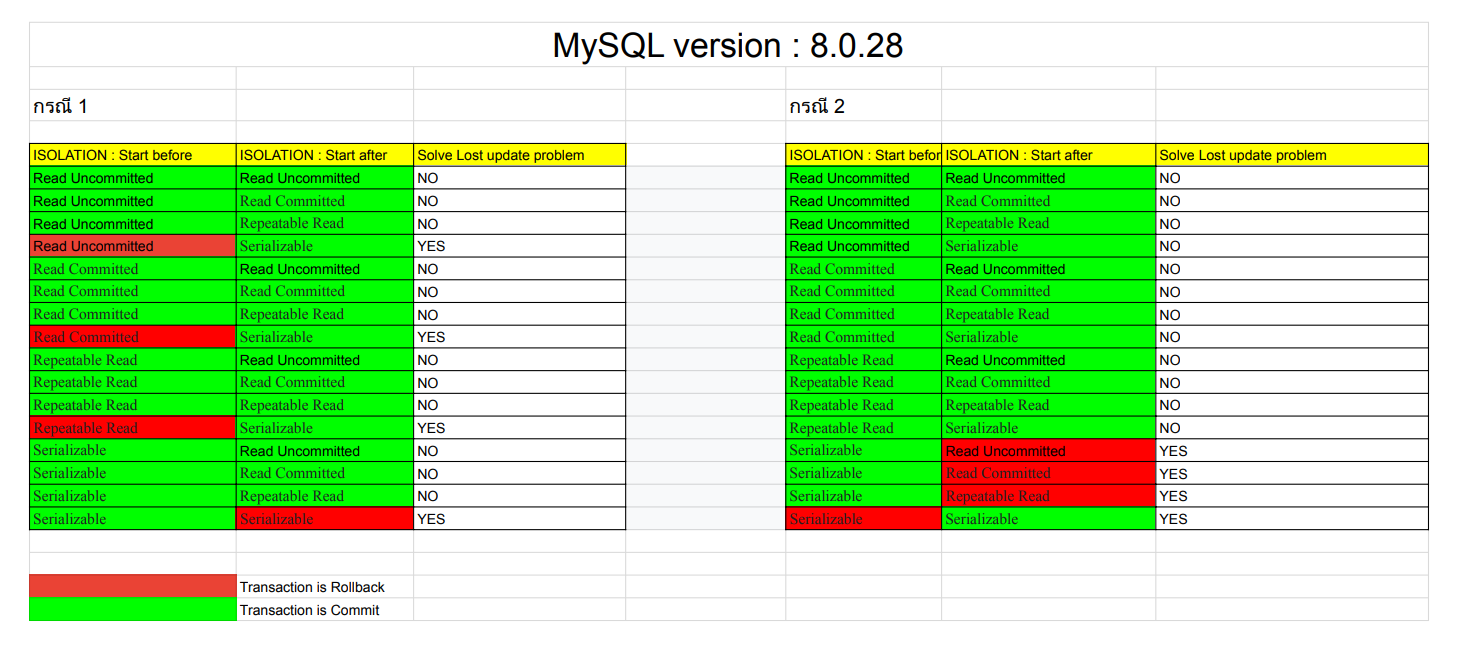
สำหรับการทดลองกับ MySQL พบว่าต่อให้เราตั้ง Isolation ระดับ Repeatable read กับทั้ง 2 Transaction แล้วก็ไม่สามารถแก้ปัญหาตัวปัญหา Lost update ได้ ส่วนตัว Isolation level ที่จะแก้ปัญหาสำหรับ Lost update ของ MySQL version : 8.0.28 จะเป็น Serializable ทั้ง 2 Transaction
** วิธีการดูว่าใช้ Isolation ไหนจัดการปัญหาได้ให้ดูว่าแถวไหนสามารถแก้ปัญหา Lost update ได้ทั้ง 2 กรณี
MariaDB version : 10.7
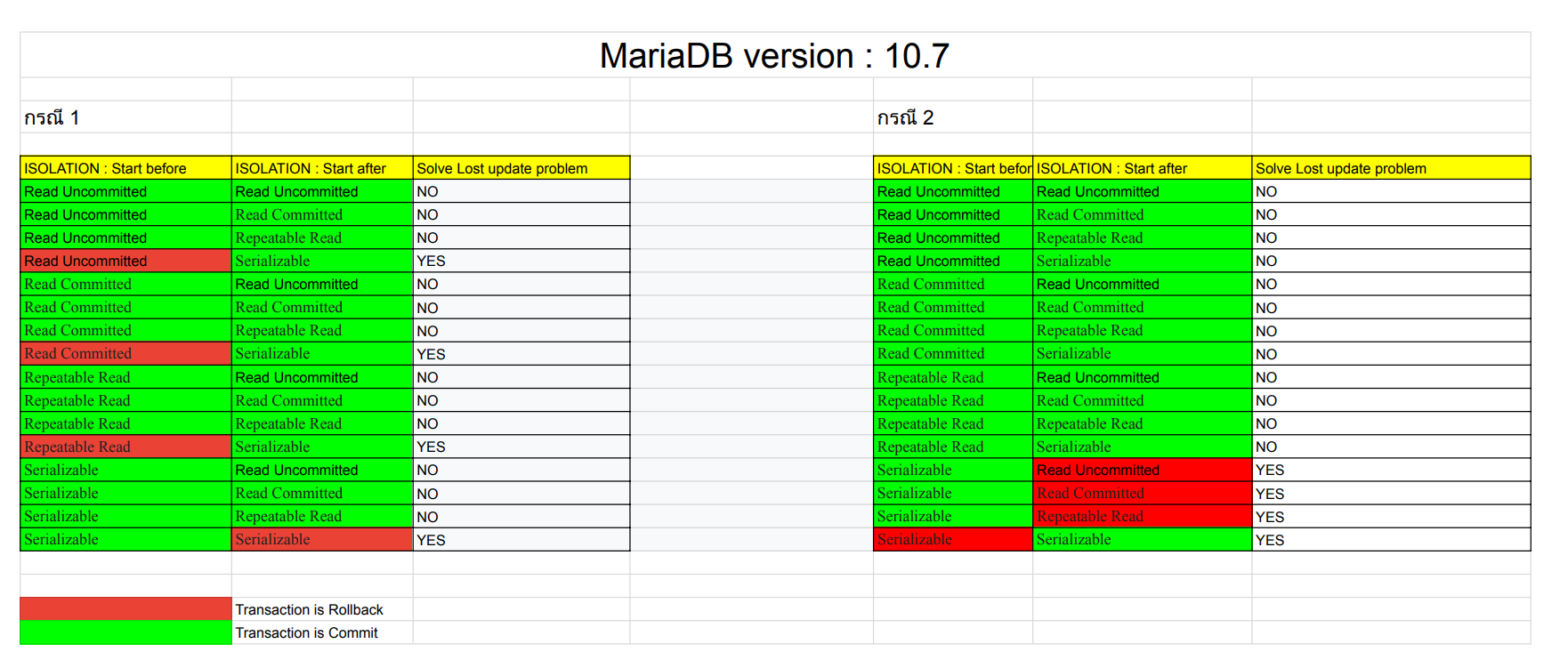
สำหรับการทดองกับ MariaDB พบว่าผลลัพธ์เหมือนกับตัว MySQL version : 8.0.28 เลย คงเพราะน่าจะมี Core การจัดการ Isolation แบบเดียวกัน ( MariaDB เกิดจากการ Fork จาก MySQL ) ดังนั้นจะแก้ปัญหา Lost update ของ MariaDB version : 10.7 ได้ต้อง Set isolation เป็น Serializable ทั้ง 2 Transaction
** วิธีการดูว่าใช้ Isolation ไหนจัดการปัญหาได้ให้ดูว่าแถวไหนสามารถแก้ปัญหา Lost update ได้ทั้ง 2 กรณี
SQL Server version : 2019
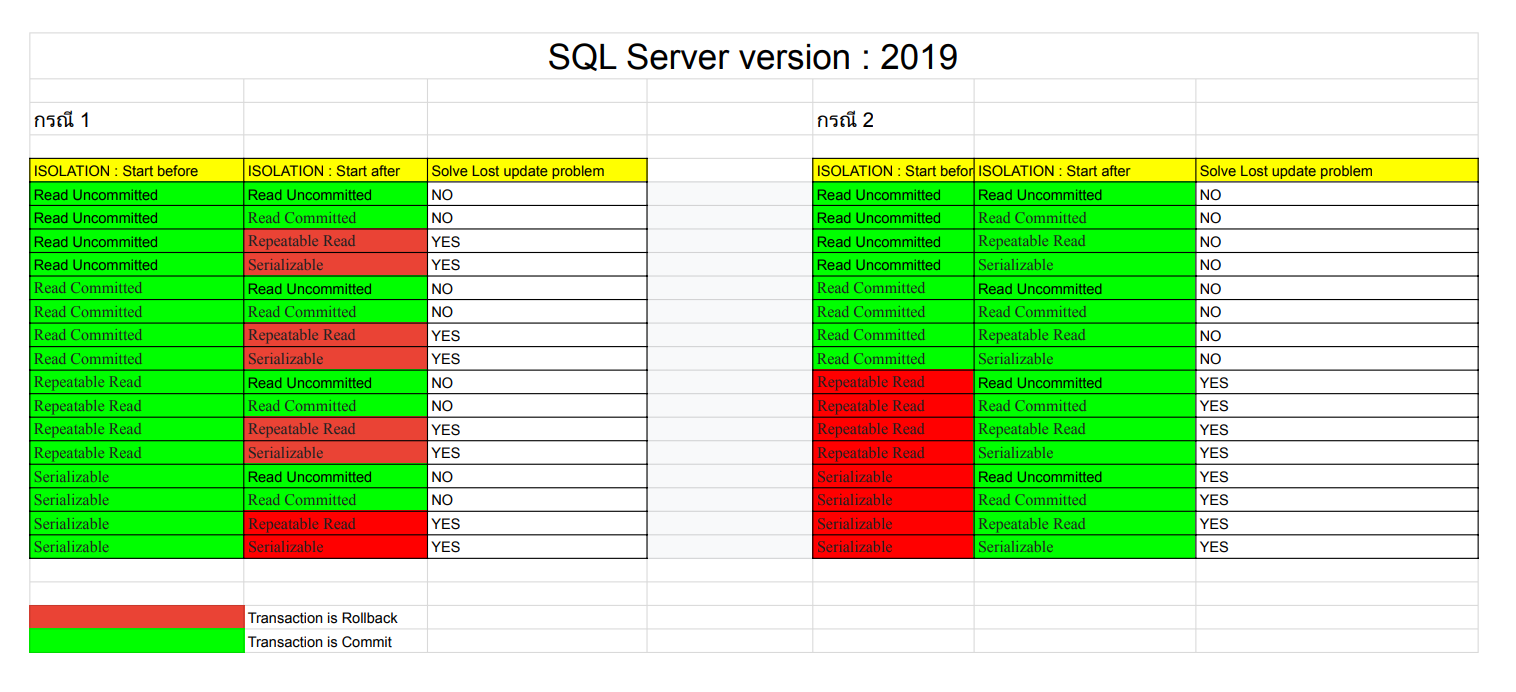
สำหรับการทดลองกับ SQL Server version : 2019 นั้นแตกต่างจาก MariaDB กับ MySQL ที่ SQL Server นั้นสามารถจัดการปัญหา Lost Update ได้โดยทำการตั้งค่าระดับ Isolation level : Repeatable Read หรือสูงกว่ากับทั้ง 2 Transaction
** วิธีการดูว่าใช้ Isolation ไหนจัดการปัญหาได้ให้ดูว่าแถวไหนสามารถแก้ปัญหา Lost update ได้ทั้ง 2 กรณี
Postgres version : 13
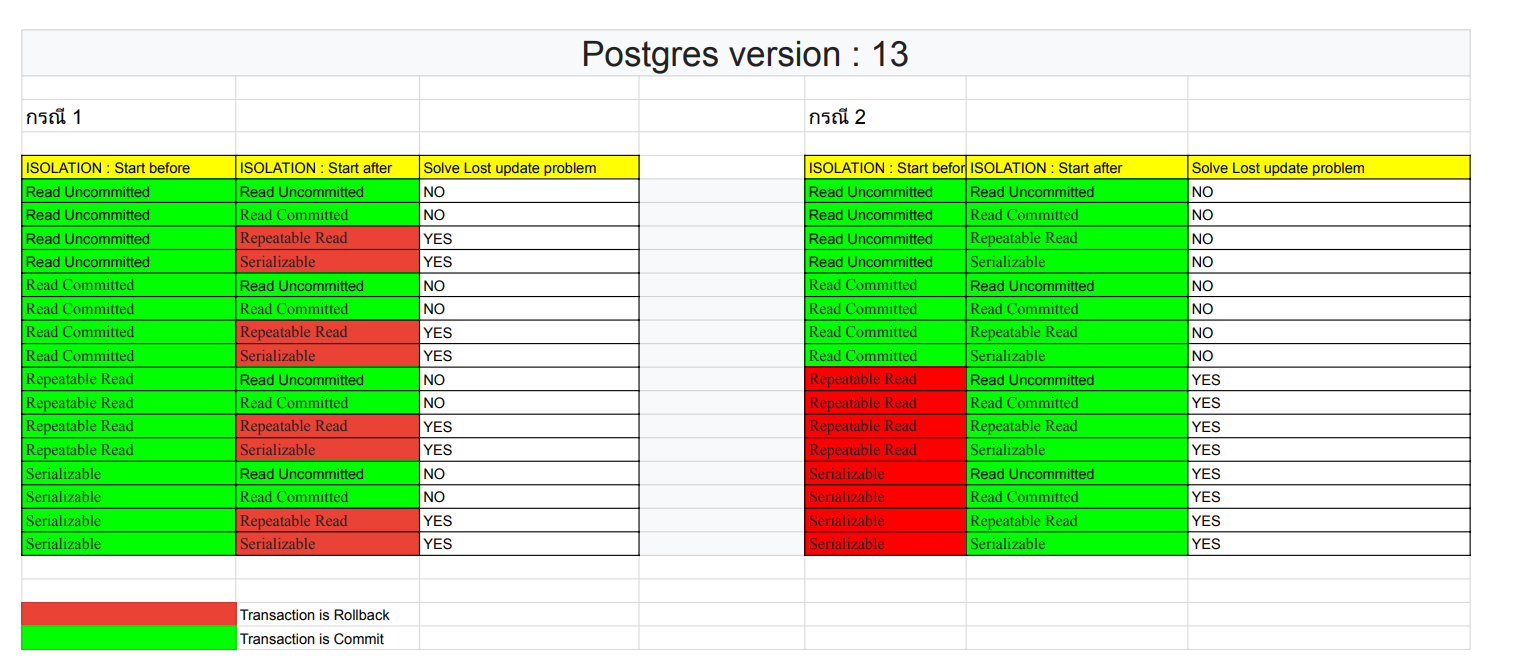
สำหรับ Postgres version : 13 นั้นให้ผลแบบเดียวกับ SQL Server เลย โดยสามารถสรุปได้ว่าสามารถจัดการปัญหา Lost Update ได้โดยทำการตั้งค่าระดับ Isolation level : Repeatable Read หรือสูงกว่ากับทั้ง 2 Transaction
** วิธีการดูว่าใช้ Isolation ไหนจัดการปัญหาได้ให้ดูว่าแถวไหนสามารถแก้ปัญหา Lost update ได้ทั้ง 2 กรณี
DB2 version : 11.5.7.0
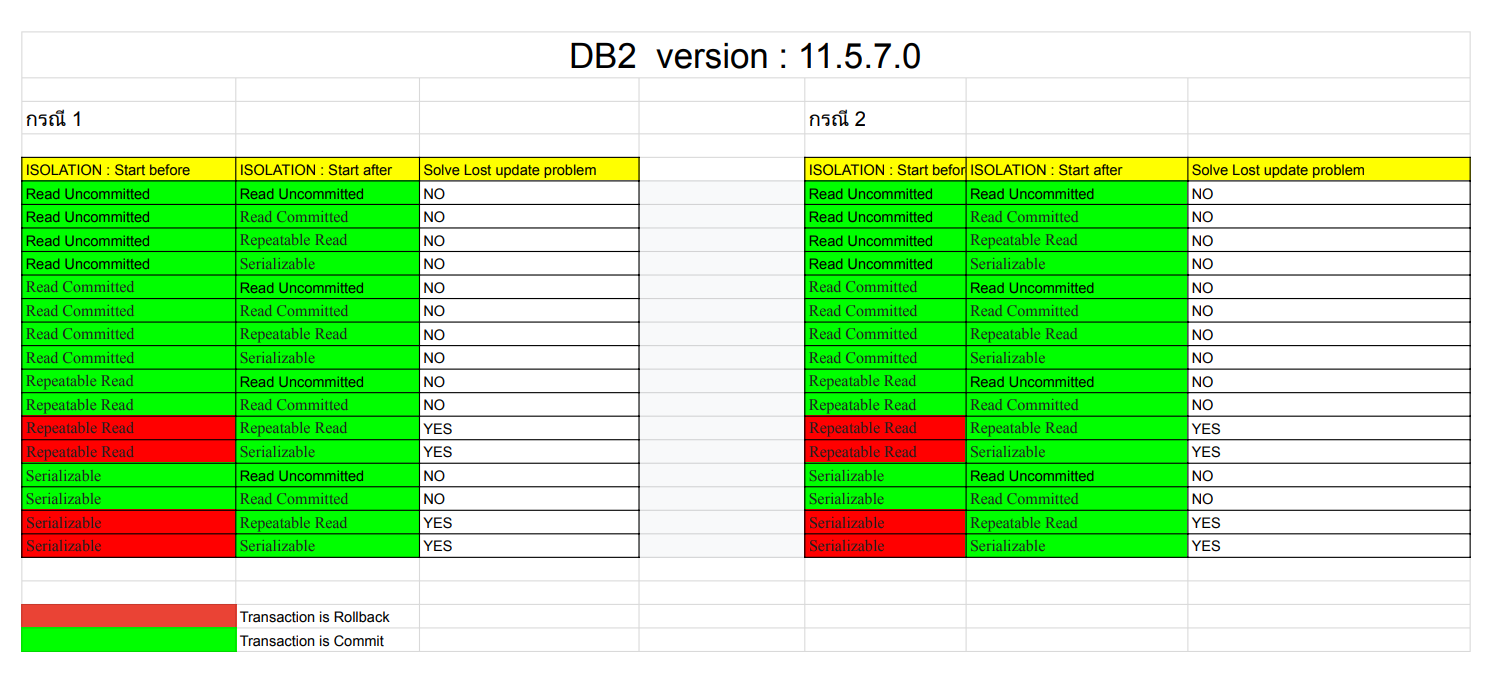
สำหรับ DB2 version : 11.5.7.0 นั้นให้ผลลัพธ์แตกต่างจาก Postgres และ SQL Server นิดหน่อย แต่โดยสรุปแล้วผลลัพธ์แล้วเหมือนกันคือ สามารถจัดการปัญหา Lost Update ได้โดยทำการตั้งค่าระดับ Isolation level : Repeatable Read หรือสูงกว่ากับทั้ง 2 Transaction
** วิธีการดูว่าใช้ Isolation ไหนจัดการปัญหาได้ให้ดูว่าแถวไหนสามารถแก้ปัญหา Lost update ได้ทั้ง 2 กรณี
สรุป
จากผลการทดลองทั้งหมดเราสามารถสรุปผลการทดลองทั้งหมดเป็นตารางได้เป็นตารางด้านล่าง
| DBMS | Isolation level |
|---|---|
| MySQL version : 8.0.28 | Serializable |
| MariaDB version : 10.7 | Serializable |
| SQL Server version : 2019 | Repeatable Read |
| Postgres version : 13 | Repeatable Read |
| DB2 version : 11.5.7.0 | Repeatable Read |
ซึ่งจะเห็นว่าตัว MySQL และ MariaDB นั้นแตกต่างจาก DBMS เจ้าอื่น ซึ่งไม่ตรงกับการใน Paper ที่ระบุไว้ว่าตัว Isolation : Repeatable Read นั้นสามารถแก้ปัญหาตัว Lost update ได้ ซึ่งผมลองไปหาอ่านคร่าวๆว่าทำไม MySQL กับ MariaDB ทำไมถึงทำไม่ได้นั้นมีคนไปตอบใน Stack overflow มีคนตอบไว้ประมาณว่าในมาตรฐาน SQL 92 ไม่ได้พูดถึงปัญหา Lost update เขาพูดแค่ปัญหา Dirty read , Unrepeatable และ Phantom เท่านั้นจึงไม่มีความจำเป็นต้อง Implement ให้แก้ปัญหา Lost update ดังนั้นใครที่ใช้ DBMS เจ้า MySQL หรือ MariaDB ถ้าจะป้องกันปัญหา Lost update ก็แนะนำให้ตั้ง Isolation เป็น Serializable หรือตอน Query ข้อมูลนั้นต้องสั่งแบบ Select for update ไปเลยเพื่อทำการบอก DBMS ทราบจะได้ทำการ Lock ข้อมูลนั้นไว้
ในส่วนของผลการทดลองที่ผลลัพธ์นั้นแตกต่างกันในแต่ละ DBMS นั้นมาจากการที่แต่ละ DBMS นั้น Implement วิธีจัดการ Isolation แตกต่างกัน บางเจ้าอาจจะใช้การทำ 2PL (Two-Phase Locking) แต่บางเจ้าอาจจะใช้การทำ Multi version data เพื่อให้เกิดความเร็ว ทำให้ผลลัพธ์ที่ออกมาจะแตกต่างกันในแต่ละกรณี แต่จะเห็นว่าแต่ละเจ้าจะพยายามรักษาภาพรวมให้ผลลัพธ์ออกมาเหมือนกัน ดูได้จาก DB2 นั้นผลลัพธ์การทำงานแตกต่างจาก Postgres และ SQL Server แต่โดยภาพรวมแล้วยังรักษาให้ Isolation ตั้งแต่ Repeatable Read ยังสามารถแก้ปัญหา Lost update ได้
Ref :